
A speech recognition algorithm or voice recognition algorithm is used in speech recognition technology to convert voice to text.
Speech recognition systems have several advantages:
- Efficiency: This technology makes work processes more efficient. Documents are generated faster, and companies have been able to save on labor costs.
- Customer service playback: Speech recognition is now used to provide basic information to users on customer service phone lines. Customers can select menus and get answers by answering questions.
- Helps hearing and visually impaired people: People with visual or hearing disabilities can now use computers to type and have text read to them out loud.
- Handsfree communication: Smartphone assistants such as Apple’s Siri and Google Assistant have made it possible to use voice to make calls, send emails, search, and more without touching the phone.
How Does A Speech Recognition Algorithm Work?
It all starts with human sound in a normal environment. Technically, this environment is referred to as an analog environment. A computer can’t work with analog data; it needs digital data. This is why the first piece of equipment needed is an analog to digital converter.
Analog to Digital Converter
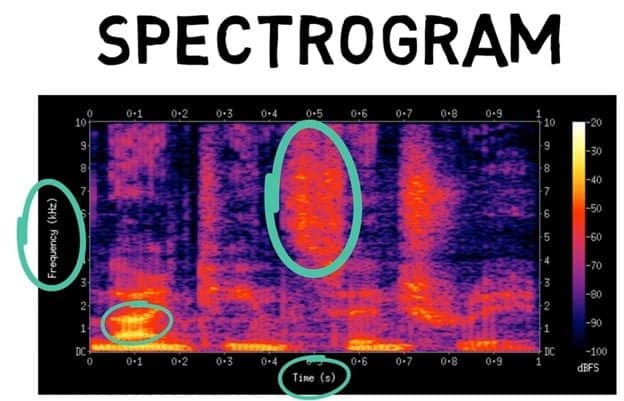
A microphone usually serves as an analog to digital converter. The conversion can be visualized in a graph known as a spectrogram. To create a spectrogram, three main steps are followed:
- The sound wave is captured and placed in a graph showing its amplitude over time. Amplitude units are always expressed in decibels (dB).
- The wave is then chopped into blocks of approximately one second, where the height of a block determines its state. Each state is then allocated a number hence successfully converting the sound from analog to digital.
- Even when the data is digitized, something is still missing. In the speech recognition process, we need three elements of sound. Its frequency, intensity, and time it took to make it. Therefore, a complex speech recognition algorithm known as the Fast Fourier Transform is used to convert the graph into a spectrogram.
As shown in the diagram below, a spectrogram shows the vertical axis’s frequency and the time on the horizontal axis. The colors denote the power that went into generating the sound. The brighter the color, the greater the power.
(Image source: Wikipedia)
The last interesting fact about the spectrogram is the time scale. It is very precise. Each vertical line is between 20 to 40 milliseconds long and is referred to as an acoustic frame.
Once the analog to digital converter has converted the sound to digital format, its work is over. It can’t understand what the words mean, and the speech recognition algorithm has to be applied to the sound to convert it into text.
Linguistics and Phonemes
A phoneme is a distinct unit of sound that distinguishes one word from another in a particular language. It is the smallest part of a word that can be changed – and, when changed, the meaning of the word is also changed. For instance, the word “thumb” and the word “dumb” are two different words that are distinguishable by the substitution of the phoneme “th” with the phoneme “d.”
Phonemes can be spoken differently by different people. Such variations are known as allophones, and they occur due to accents, age, gender, the position of the phoneme within the word, or even the speaker’s emotional state.
Phonemes are important because they are the basic building blocks used by a speech recognition algorithm to place them in the right order to form words and sentences. Speech recognition does this using two techniques – the Hidden Markov Model and Neural Networks.
Hidden Markov Model in Speech Recognition
The Hidden Markov model in speech recognition, arranges phonemes in the right order by using statistical probabilities. To do this, it uses three different layers.
In the first layer, the model has to check the acoustic level and the probability that the phoneme it has detected is the correct one. As stated before, the variation of phonemes depends on several different factors, such as accents, cadence, emotions, gender, etc.
In the second layer, the model checks phonemes that are next to each other and the probability that they should be next to each other. For example, if you have the sound “st,” then most likely a vowel such as “a” will follow. It’s less likely or even impossible for an “n” phoneme to follow an “st” phoneme – at least in the English language.
Finally, in the third layer, the model checks the word level. That is, whether words next to each other make sense. It does this by checking the probability that they should be next to each other. For example, it will check if there are too many or too few verbs in the phrase. It also checks adverbs, subjects, and several other components of a sentence.
The model checks and rechecks all the probabilities to come up with the most likely text that was spoken. You can see this in real-time when you dictate into your phone’s assistant. You may notice that the words at the beginning of your phrase start changing as the system tries to understand what you say.
This model is a great fit for the sequential nature of speech. However, it is not flexible. Also, there is such a wide variety of phonemes and potential combinations of them that it still has a long way to go before it can be regarded as perfect.
Artificial Neural Networks
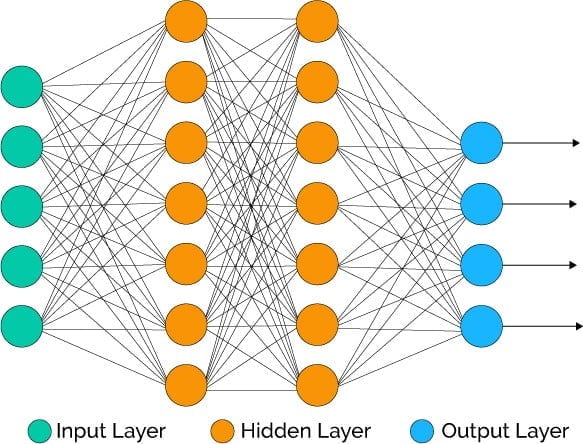
The inner workings of an artificial neural network are based on how the human brain works. A neural network is a network of nodes that are built using an input layer, a hidden layer composed of many different layers, and an output layer.
The connections all have different weights, and only the information that has reached a certain threshold is sent through to the next node. If a node has to choose between two inputs, it chooses the node’s input with which it has the strongest connection. In some systems, it can also take both inputs and come up with a ratio.
(Image source: Xenonstack.com)
The advantage of neural networks is that they are flexible and can, therefore, change over time. This means that the neural network has to be trained as all the different connections initially have the same weight. Input is given to the neural network, and the desired output specified. The neural network then does its thing and comes up with a certain output that is not the same as the desired output because more training is needed. This difference is the error. The neural network understands that there is an error and therefore starts adapting itself to reduce the error. For the neural network to keep improving and eliminate the error, it needs a lot of input.
This requirement for lots of input before it becomes perfect is one of the downsides of neural networks in speech recognition. The other downside is that it is a bad fit for the sequential nature of speech – but, on the plus side, it’s flexible and also grasps the varieties of the phonemes. Therefore, it can detect the uniqueness of accents, emotions, age, gender, and so on.
The weaknesses of Neural Networks are mitigated by the strengths of the Hidden Markov Model and vice versa. This is why the Hidden Markov Model and Neural Networks are used together in speech recognition applications.




{kind=link}