
Big data is a powerful tool. Defined as very large (huge) datasets that can be analyzed computationally to reveal patterns, trends and associations – especially in connection with human (i.e. customer) behavior and interactions – it can lead to substantial breakthroughs and more solid business decisions for those who learn how to leverage it properly.
Having the ability to analyze and draw insights from all available data – both structured and unstructured, online and offline – helps organizations grow their business and make informed strategic moves. A powerful platform enables organizations to ask and answer more questions, allows for a more accurate decision-making process, and can truly empower the workforce.
As such, it’s no surprise the market is growing. Revenue for big data software and services are projected to increase from $42 billion in 2018 to $103 billion in 2027, attaining a compound annual growth rate (CAGR) of 10.4%. What’s more, as part of this forecast (reported by Statista), Wikibon estimates that the worldwide market is growing at an 11.4% CAGR between 2017 and 2027 – from $35 billion to $103 billion.
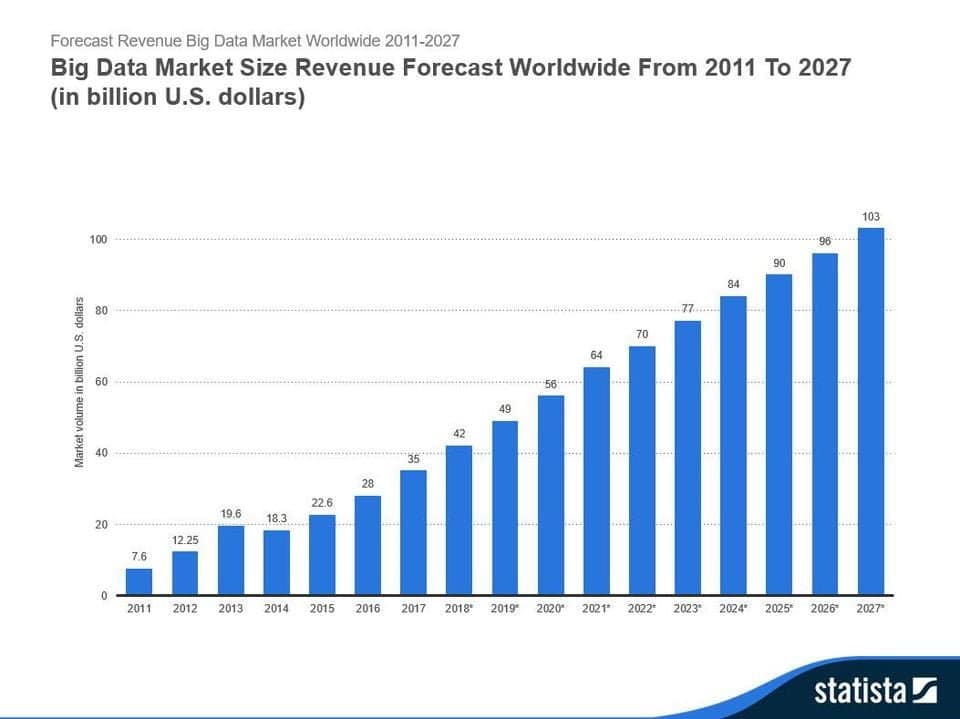
(Image source: statista.com)
The growth is indeed unstoppable, and organizations across a wide variety of industries are set to benefit – provided they’re prepared. Sales and marketing, research and development, supply chain management, workplace management and operations are where advanced analytics, are making the greatest contributions to revenue growth today, according to McKinsey Analytics’ study ‘Analytics Comes of Age’.
But big data and advanced analytics are of course complicated subjects enough in their own right, let alone when it comes to figuring out the best strategies for implementing big data initiatives at the enterprise.
Where do you start with it all? Below, we’ve put together a list of five great blogs – all published in the past few months and written by some of the best brains in the business – that are great reading if you want to get your organization going. We’ve chosen articles that will pave your way to a better understanding of how and where big data can be a boon to your organization, are insightful, well-written, and – importantly – easy-to-digest. The articles serve as a great jumping-off point for some of the most important strategies and concepts that will help you hit the ground running, but, in addition to these, we also point you in the direction of some more advanced further reading that builds on the topics covered. Let’s dive in.
- Oracle – 6 Steps to Data-Driven Transformation

To begin, you need a game plan. The Fourth Industrial Revolution – which we are living through right now – will completely change the way business is done and organizations are run over the next five to ten years. And data is at the heart of it.
Oracle is one of the world’s largest and most influential big data players in the game today, specializing in developing database software and technology, cloud engineered systems and enterprise software products.
- IBM – What’s the Difference Between Data Lakes and Data Warehouses?

(Image source: ibm.com)
For big data, you need big storage, and both data lakes and data warehouses are widely used for this purpose. But they are not interchangeable terms.
In essence, a data lake is simply a vast pool of raw data, the purpose for which is not yet defined, whereas a data warehouse is a repository for structured, filtered data that has already been processed for a specific purpose. But we’re just scratching the surface here.
Drilling down a little deeper, IBM’s recently published post ‘What’s the Difference Between Data Lakes and Data Warehouses?’ outlines the key differences, as well as the business cases both for and against data lakes.
For more advanced reading, IBM also offers a free data lake eBook to download.
- Oracle – 7 Data Lake Best Practices (+ Further Data Warehouse Reading)
Data lakes are powerful things – not only are they a cost-effective way of storing your data, they can also hold structured and unstructured data, internal and external data, and enable teams across the business to discover valuable new insights.
But there’s a right way and a wrong to go about building a data lake. In a post from earlier this year, Oracle gathered insights from data lake experts Larry Fumagalli and David Bayard of Oracle’s Cloud Platform Team (Bayard has since moved to AWS) to put together a list of ‘7 Data Lake Best Practices’ for enterprises.
Here’s the summary:
- Start with a Business Problem or Use Case for Your Data Lake
- Line Up the Right Resources
- Remember the Difference Between a Data Lake and a Database
- Don’t Forget About Object Storage and the New Data Lake Architecture
- Don’t Forget to Secure Your Data Lake
- Think About Buy vs. Build
- Consider the Full Data Management Lifecycle
However, if you read the IBM post, you might still decide that you need a data warehouse – either instead of a data lake, or as well as one. If this is the case, then we direct you first towards Panoply’s excellent post ‘Which Type of Data Warehouse Is Right for You?’ to get the lowdown on your options, followed by DZone’s ‘Best Practices for Setting Up a Data Warehouse in the Cloud’.
Panoply also offers a free ‘Data Warehouse Trends Report 2018’ for further data warehouse reading.

(Image source: learn.panoply.io)
- Teradata – Reimagining Analytics and Herding Unicorns
Teradata is another big player in the big data world, providing database and analytics-related products and services. The company’s blog is a treasure trove of incredibly insightful yet easy-to-digest content with a large focus on data and business analytics.
Its most recent post (at time of writing) focuses on one of the biggest challenges organizations face on their journey – data access.

(Image source: teradata.com)
Access to data is what makes or breaks data intelligence, and in his ‘Reimagining Analytics and Herding Unicorns’ post, Chris Twogood, SVP Global Marketing at Teradata, considers the roadblocks to data access and what organizations can do to overcome them (and throws in a little plug for a Teradata product, too).
Further reading: Teradata’s Global Survey: Analytic Insights Remain Trapped in Complexity and Bottlenecks
- Forbes – Getting Data Science Right: How to Structure Data Science Teams for Maximum Results
In order to take advantage of data, organizations need to build, engage, and retain a strong team with the right skills. But what are the roles that make up such a team?
Writing in Forbes, Head of Global Data Science at Ancestry Azadeh Moghtaderi describes three critical roles organizations need to fill in order to realize a data-driven transformation. These are Data Scientists, Data Engineers, and Machine Learning Engineers.
Moghtaderi defines these roles, explains their differences, and explicates what is required for a data science team to be successful. Read the full post here – ‘Getting Data Science Right: How to Structure Data Science Teams for Maximum Results’.
Over in Hackernoon, Cassie Kozyrkov, Chief Decision Intelligence Engineer at Google, provides us with some further reading, expanding from three to ‘10 Data Roles in AI and Data Science’ as she walks us through the roles that need to be filled when growing a winning data science team.
Final Thoughts
Big data isn’t just a buzzword. It’s here to stay, and organizations need to be planning their journey now if they are to remain competitive over the coming five to ten years. If you want to improve your knowledge, you need to start reading. The blog posts outlined above are a great place to start, and the further reading suggestions will expand your knowledge from there. But this is just the beginning. Hopefully, this article will give you some good starting points for discovering some great blogs and influencers, but you’ll need to keep exploring, keep reading, and ultimately start strategizing at some point in the very near future.



