
What Is Speech Recognition?
What is speech recognition? Well, the first important concept to understand about speech recognition is that it is an input method. It is a way for humans to interact with computers, similar to other common input methods such as a mouse, keyboard, and telephone touchpad.
The difference being that, rather than using your hands, speech recognition lets you use your voice to interact with a computer system.
Much like when you click a button on a computer and the click elicits a response based on the computer’s programming, in the speech recognition process, the computer recognizes the words that you say and responds as it has been programmed to do.
There are several popular examples of speech recognition applications, including speech recognition Windows 10 and Google Speech to Text, and many more, with many developers offering speech recognition software free for personal use.
While early speech recognition applications had some serious limitations, the technology in this field is now evolving rapidly. It’s hard to say which is the best speech recognition software so far, but there are some potential winners, such as Apple Dictation, Amazon Transcribe, Google Speech to Text on Google Cloud, and Windows Speech Recognition.
Speech Recognition vs Voice Recognition
These terms are often used interchangeably. But, in the speech recognition industry and within academic circles of scholars, linguists, and computer scientists, there is a big distinction. Speech recognition refers to computers being able to understand the words that you say. The computer translates the sounds that come from your voice into pre-defined words to recognize.
So, what is voice recognition? Voice recognition is the process of recognizing speakers based upon their voice and speaking styles. We all have distinct methods of speaking. That’s how your mom on the phone sounds different from your favorite talk show TV host.
The voice is like a fingerprint – specific to a particular individual. Voice recognition technology allows computers to recognize the unique characteristics of voices and match them to individuals.
A good example of ways voice recognition technology is used is in biometric authentication for security purposes.
So, in a nutshell, speech recognition is about computers recognizing what was said, while voice recognition is about recognizing who said it.
Reasons for Speech Recognition
Speech recognition is a natural interaction. Unlike other input methods, you don’t have to be trained on how to speak. Spoken language is, therefore, a great way to interact with a computer system. You just say what you want, and the commands are executed.
It’s also convenient – especially for telephone applications. For example, when your hands are occupied (e.g. when driving) and all you can use is a headset or earpiece, you don’t have to “press 1 for customer service, 2 for sales enquiries, etc.” – you simply use your voice.
Additionally, speech recognition helps application designers make their apps easier for people to use. For example, using personal assistants like Apple’s Siri and Google Assistant, people can simply say what they are searching for or issue a command.
How Speech Recognition Works
Speech recognition allows you to have an actual conversation with a non-living object. A few decades ago, computers had limited processing power and memory capacity. With improvements in processing power, storage space and the rise of natural language processing (NLP), this has all changed.

So, what gives a computer the power to understand human sounds and make sense of it all? How speech recognition works is that NLP technology allows for the recognition and translation of speech to text.
The most well-known example of speech recognition software is that which is found in smart speakers like Apple’s Siri, Amazon’s Alexa, Google’s Assistant, and Microsoft’s Cortana. Another example of speech recognition software is Google Translate.
But, how does speech to text work exactly? How can a computer recognize your speech? It is a three-part process which we explain in detail below to help you understand how speech to text works.
1. Audio is broken down into individual sounds
When people speak, they create vibrations in the air. A device known as an analog-to-digital-converter (ADC) transforms the sound waves into binary data that the machine can understand.
2. These sounds are then converted into a digital format
The ADC also filters the sound to remove unnecessary noise. In addition, it normalizes the sound and speed of the speech to match the pre-recorded samples in the device.
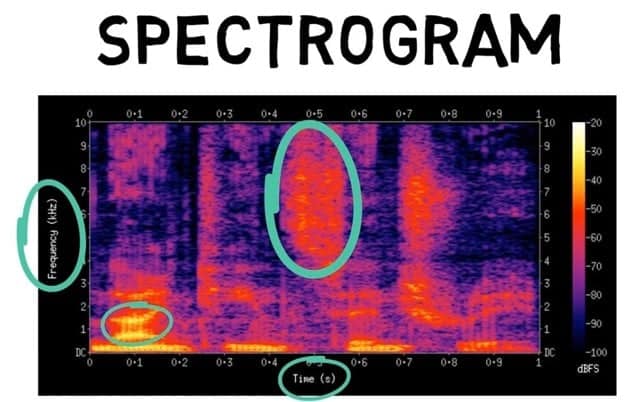
It then separates the data into different bands of frequencies which the spectrogram analyzes further. On a spectrogram, you have time on the x-axis and the frequencies of a sound on the y-axis (high pitch vs low pitch).
All words are made up of distinct vowel sounds and each has different frequencies that are recorded on the device. Bright areas on a spectrogram signify high frequencies while darker areas signify low frequencies.
All vowel sounds have different frequency patterns that can be pre-programmed into the computer allowing it to recognize when a spoken sound matches a specific vowel sound.
3. Algorithms and models are used to find the most probable word fit in that language
A computer runs these phonemes through complex algorithms that compare them to words in its pre-built dictionary. But there is a catch – human language isn’t so simple.
We all know that humans speak with different accents, dialects, mispronunciations, and these variations aren’t necessarily in the computer’s dictionary.
This is where models such as the Hidden Markov Model come in handy, which help computers understand the intricacies and nuances of human language.
To respond to the words with valuable output, the computer makes use of natural language processing (NLP). Every day, we each speak hundreds of sentences and talk to many different people.
We also understand the parts of a sentence and which type of words come together to create a sentence that makes sense. A sentence is made up of a noun phrase and a verb phrase.
These can be broken up into individual parts of speech.Let’s take an example using the sentence, “The man leaves the bank”. “The” is an article, “man” is a noun, and “leaves” is a verb; “the” is another article, and “Bank” another noun.
“The” and “man” are combined into a noun phrase and “the” and “Bank” into another noun phrase. The verb “leaves” and the noun phrase “the bank” can turn into a verb phrase.
Together, the noun phrase “the man” and the verb phrase “leaves the bank” become a full sentence. Quite confusing when written down – but, much like our brains, NLP technology makes sense of it all almost instantaneously.
The techniques used broadly fall into the categories of Part-of-speech tagging and Chunking. These parts of speech are what give natural language processing the power of understanding context.
While a non-NLP powered computer may be confused as to whether the word “leaves” is referring to the act of exiting a place or the plural of a leaf, and whether the word “bank” is referring to a building that stores money or the land next to a river, a computer powered by NLP will recognize the fact that leaves in this context is a verb and not a noun.
By analyzing hundreds of sentences and different word patterns, it can figure out that it is far more uncommon for a person to say that they are leaving a bank of a river than it is to say leaving a bank that stores money.
A computer can then see that the name subject of the sentence is the man and that he is doing the action of leaving a place – which, in this case, is a bank.And, it’s not just Part-of-speech tagging and Chunking that allows NLP to figure out the meaning of a person’s words.
Other techniques can broadly be classified into two categories – syntax and semantics.Individual words, parts-of-speech, and placement in a sentence give a computer knowledge and context as to what the sentence is trying to say.
But, how does a computer know what the parts-of-speech are? And how does it figure it all out even if it does know the parts-of-speech? The answer lies in big data.
In today’s world, there is a lot of data available. A programmer can gather all sorts of words, phrases, sentences, grammatical rules, word structures, and input all this data into an algorithm.
Using this information, the algorithm can figure out what kind of words usually end up next to each other, how a sentence should be formed, why certain words fit into a sentence better than others, and so forth. This is precisely how a computer will eventually figure out the context.
(Note: The previous information also applies to voice recognition, how it works, and also answers the question, how does voice recognition software work?)

Syntax
There are three categories of syntax – tokenization, stemming, and lemmatization. Tokenization can be split into a further two categories, sentence tokenization, and word tokenization.
Sentence tokenization refers to splitting a paragraph into distinct sentences, while word tokenization is separating a sentence into distinct words. This allows the computer to learn the potential meanings and purpose of each unique word.
Stemming refers to the process of reducing a word to its stem or root. It does this by chopping off universal prefixes and suffixes. Stemming is a powerful technique, but is solely based on common prefixes and suffixes. It sometimes cuts necessary components and changes the meaning of the original word.
Lemmatization helps solve this problem. Instead of chopping up beginnings and endings, lemmatization reduces a word to its root form by analyzing the word morphologically.
For example, “Am”, “Are”, and “Is”, are root forms of the word “Be”. This can be observed through lemmatization. Stemming would not be able to figure this out since chopping off any letters would not output the word “Be”.
Semantics
Semantics can be broadly categorized into Named Entity Recognition and Natural Language Generation. Named Entity Recognition allows the computer to categorize specific words in a sentence.
This is helpful for a word such as “Google” which can be referred to as an organization or a verb. Natural Language Generation is a process through which a machine produces natural human language.
It uses math formulas and numerical information to extract patterns and data from a given database and output understandable human language text.
Natural language processing enables a machine to take what you are saying, make sense out of it and formulate a statement of its own to respond to you.
What Is Text to Speech?
What is text to speech? Text to speech software takes the written text and transforms it into speech. There are hundreds of text to speech online applications and numerous text to speech free downloads are available.
This technology offers a ton of benefits for people who prefer listening to reading. It is also great for people who want to listen to a piece of text as they perform another task. For example, you can listen to the audio of a book while driving.
Text to speech is also one of the ways that visually impaired individuals consume content. It is known to enhance literacy skills, improve reading comprehension, accuracy, and the ability to recall information.
Text to speech can improve word recognition skills and increases pronunciation capabilities.
Many applications can convert text to speech. Google Text-to-Speech is one such tool that enables applications to read out the text on your device’s screen.
Text to speech should not be confused with speech to text. The latter refers to speech recognition where a computer uses your voice input to execute commands. Another potentially confusing term is “voice to text”. What is voice to text? Simply, speech to text can also be referred to as voice to text.
There are also dozens of speech to text individual applications that help with speech to text transcription or to transcribe audio to text. To begin learning how to speech to text, read the documentation in these applications.
Advantages of Speech Recognition and Speech to Text
Speech recognition technology has transformed communication and decreased the time it takes to complete tasks. It has also allowed people to use technology in ways that weren’t previously possible. The following are some benefits of speech recognition and benefits of voice recognition.

Helping Disabled Persons
The most obvious benefit is that speech recognition technology has made it possible for people with disabilities to type and operate computers using their voices as input.
Before this technology, many people with certain physical impairments could not use computers effectively, if at all. Speech recognition has brought equity to these people and allowed them to participate in our highly technological society.
Spelling
Using advanced algorithms and natural language processing, speech recognition applications ensure we always use the correct spelling and use words appropriately. Voice recognition has made it possible to write with precision and clarity. This saves lots of time, especially at the workplace.
Enhanced Speed
For people lacking typing skills or are slow typers, voice recognition is a game-changer. Long hours spent typing is also known to cause musculoskeletal health conditions. Speech recognition is, therefore, a safer and faster alternative to getting your thoughts down in print.
Specialization
Speech recognition is also revolutionizing many industries. For example, in the field of medicine, doctors can now add medical notes directly into a patient’s files without having to type or write anything down.
They simply speak into a voice recorder and the patient’s Electronic Health Record is automatically updated. This has allowed doctors to spend more time providing treatment and saving lives.

History of Speech Recognition
In 1791, the first acoustic mechanical speech machine was built by Wolfgang Von Kempelen. It consisted of bellows, a reed and a synthetic mouth made of rubber. With a skilled user, this machine could produce full sentences in English, French, and Italian.
After Kempelen’s device there was a lull in inventions for over a century, until, in 1922, a device known as Radio Rex was invented. This was the first machine capable of recognizing speech.
It was a toy dog controlled by a spring and mounted on an electromagnet. The electromagnet was interrupted when there was an acoustic signal of 500 hertz. So, if someone said the word “rex” the dog would pop-up since the word “rex” is about 500 hertz.
In 1952, we had the Audrey system built by Bell Labs. This device could recognize only ten digits.
Next came IBM Shoebox – released to the public in 1962 – which could understand 16 words, the digits 0 to 9, and perform mathematical calculations. This early computer was developed 20 years before the development of the IBM personal computer in 1981.
In 1962, the IBM 704 was invented. This was the first machine that could sing a song – ‘Daisy Bell’.
By the 1970s, machines were able to recognize about 1,000 words. One such tool, named Harpy, was developed at the Carnegie Mellon University in Pennsylvania with the aid of the US Department of Defense.
About ten years later, the same group of scientists developed a system that could not only analyze individual words but entire word sequences. Among the earliest virtual assistants that applied this technology were automated attendants – the canned automated voices we still hear when we dial a customer service number.
In the 1990s, digital speech recognition was a new feature of the personal computer with the likes of Microsoft, IBM, Philips, and Lernout and Hauspie competing for customers. The latter was a Belgian-based speech recognition company that went bankrupt in 2001.
The launch of the first smartphone, the IBM Simon in 1994, laid the foundation for smart virtual assistants as we know them today. The history of voice recognition, where computers could recognize particular speakers, can be traced to this point.
Siri on the iPhone 4S was the first modern incarnation. Google Now arrived a year after Siri, bringing voice recognition to Android. Today, voice assistants are everywhere.
Speech Recognition Applications
There are numerous speech recognition applications today. These are transforming human interaction with devices, cars, homes, and work.
Speech recognition voice assistants have become a ubiquitous part of our lives.
They help us complete basic tasks and respond to our queries. Conventional digital assistants can access information from massive databases.
They also rely on deep learning speech recognition and machine learning speech recognition technology to solve problems in real-time, enhance the user experience, and boost productivity.
Popular speech recognition applications include:
Apple Siri
Siri stands for Speech Interpretation and Recognition Interface. The application is invoked by saying the phrase “Hey, Siri”. Siri-enabled iOS apps have specific functions, such as messaging, note-taking, scheduling, etc.
Google Assistant
Google Assistant is an Android speech recognition application. It ships as a standard feature on all Android devices and is invoked by the phrase “Ok, Google”.
Microsoft Cortana
Cortana is a Microsoft application and was named after the AI character from Halo Games. It was created for Windows Phone 8.1 and now comes as standard on all applications running on the Windows operating system. Cortana is invoked using the phrase “Hey, Cortana”.
Cortana is said to be the most human-like of all speech recognition applications. It has a team of writers, screenwriters, playwrights, novelists, and essayists who are trying to provide more human-like interaction.
Amazon Alexa
Alexa is available on Amazon Echo and Fire TV. Any developer can contribute to the Amazon Skills library and hence assist with further development.
In addition to these well-known applications, there are many more, such as java speech recognition, java voice recognition and other speech to text applications that offer cross-platform support.
Speech to Text Software
Text to speech software refers to computer programs that scan text and then read it aloud using speech synthesis technology.
On the other side of the coin, speech to text software, speech transcription software and voice to text software all refer to any computer program that inputs audio and returns a written transcript. It is the best way to get a fast, affordable, and easy transcript from a voice sample.
There are hundreds of transcription software services online that offer this service and many companies offer a speech to text software free download.
But, the best speech to text software must be able to provide an accuracy rate of at least 90% for clean recordings that are not heavily accented. A good speech to text app will also offer transcription for many languages.
Examples of free speech to text software include Google Text to Speech on Google Cloud and Amazon Transcribe. These two are often regarded as the best transcription software due to the generous free tiers they offer. However, usage is only free up to a certain level, after which the customer is billed for additional usage.
However, speech to text apps and voice to text applications, in general, are yet to reach the accuracy levels of human transcription.
Speech to Text Problems
There are many complaints of voice to text not working. In some cases it’s human error, other times it’s technology glitches.
Some of the things you can quickly and easily check:
- Is your microphone plugged in?
- If the microphone has a mute button, has it been pressed?
Once you’ve ruled that out, consider your voice – are you speaking loudly? Clearly? Is there a slight but perceptible pause between words? Are you hoarse or losing your voice?
While the technology is impressive, it is not immune to bugs especially related to variances in how you speak.
The best solution for speech to text problems is to contact the support network for your particular technology.
How Does Speech to Text Software Work?
How does speech recognition work? The speech recognition process involves multiple steps. Speech creates vibrations that are picked up by an analog-to-digital converter (ADC).
The ADC samples the sound and takes frequent detailed wave measurements to complete conversion into digital language. The software applies filters to distinguish different frequencies and relevant sounds because not all sound picked up comprises a part of speech.
The sound is then segmented into hundredths or thousandths of seconds and matched to phonemes. Each phoneme is analyzed in relation to other phonemes and then run through complex algorithms to match them to sentences, words, and phrases in a database. The system then picks an output that best represents what the person has said.
How to do speech to text as a user? Simply speak into your device with a speech to text application enabled and watch your spoken words transform into written text.
How Does Voice Recognition Work?
How voice recognition works is that the software is initially “trained” to recognize a particular person’s voice. For example, when you create a new Google account and add it to a new Android device, Google Assistant will prompt you to record your voice by speaking a series of phrases into the microphone. This way, the application learns your accent and is acquainted with your manner of speech.
What Does Voice Recognition Do?
When you speak, the application “listens” and then follows the same process to output text. Voice recognition is more accurate than speech recognition due to the “training” process. With long-term use, voice assistants can feel like a real human assistant.

Voice Recognition Software
Voice recognition has taken years to develop to a point where it is good for mass adoption. Every breakthrough in years past has left a bitter taste in the mouth as users have found it to be clunky.
But, voice recognition has finally gained widespread adoption over recent years due to great advancements in technology.
Early voice recognition software had a limited dictionary size and could not differentiate context. Fortunately, by the late 1990s computers had evolved to have lots of storage and processing power, allowing voice recognition software to comprehend more natural speech instead of forcing users to speak slowly and unnaturally.
Now, technologies like Apple’s Siri and Cortana, a Windows speech recognition application, don’t depend on limited dictionaries or mobile device processors.
Instead, they make use of enormous cloud databases that store billions of words, sentences, and phrases. These cloud servers have nimble CPUs to precisely comprehend what you mean.
For example, Google speech recognition software can learn from search engine entries and can also discern a variety of accents. So, you can use it whether you are from Texas, New Delhi, or Zanzibar.
But, it goes further than that. When you ask your voice recognition app for a sports score, how does it know to respond with information about your favorite team instead of giving you information about a random sports score?
Instead of listening to just one word at a time, it listens to other words as well for context. It then uses probability to determine what you are trying to say.
This is a technical process that uses complex mathematical models. Google, for instance, uses an artificial neural network that works like a human brain using digital neurons to learn and understand what humans are saying.
This can be seen when Google Assistant changes what it thinks you said in real-time as you continue talking. And, it gets better. Growth in processing power has made real-time translation possible.
You can talk to game characters using a virtual reality headset. Tracking emotions – where a computer uses the timing and pitch of your voice to understand how you are feeling – is now also possible.
Uptake has even been seen in the Air Force where voice recognition technologies are deployed in fighter aircraft so that pilots can concentrate on the mission objectives instead of fiddling with instruments.
But although voice recognition has come a long way, it has presented several problems that need to be dealt with. Two stand out above the rest:
- Developers need to find ways to filter out background noise so that you still get accurate results even when you are standing on a noisy street.
- The second issue is privacy. Many types of voice recognition software come with deep learning capabilities. They learn user habits and improve their performance. This, combined with cloud processes, can lead to real concerns. For example, a few years ago, Samsung Smart TVs had a privacy policy that suggested the Samsung voice recognition system was able to monitor conversations occurring within close proximity of the TV.
Streaming Speech Recognition
Streaming speech recognition refers to the real-time streaming of audio to a speech-to-text software program. Text recognition happens simultaneously as the speech plays.
A good example of this technology is Google speech to text streaming on YouTube. When you enable the closed captions button on live YouTube video, you will see Google speech recognition and Google voice recognition working in real-time.
Microsoft speech recognition also has streaming speech technology as do many speech recognition python applications.
Streaming speech recognition helps save time where you don’t want to have to wait to transcribe the entire audio.
It also helps people with impaired hearing to follow live broadcasts.
Automatic Speech Recognition
ASR (automatic speech recognition) refers to speech recognition programs that analyze audio and convert it to text without human intervention.
There are four key differences between automatic speech transcription and human transcription services.
Cost
Human transcription costs a lot more than automatic speech transcription. Most automated speech recognition services have a free tier in terms of audio minutes or hours. Once these are exhausted, the service is costed on a per-audio-hour or -minute basis.
Time
ASR is also much faster than human speech to text transcriptions. A highly skilled human transcriber can transcribe one hour of audio in 4 to 6 hours, while automatic speech recognition software can get it done in a few minutes.
Quality
While automatic speech transcription is cheaper and faster, it has a much lower level of accuracy. Speech to text software programs needs clear audio to output high accuracy.
Unfortunately, most recorded audio is rarely 100% clear. There is background noise, heavy accents, false starts, and stutters. As a result, ASR will rarely deliver 99% accuracy. Professional human transcription, on the other hand, usually can.
Versatility
ASR can only output verbatim transcript whereas a human can offer a wider spectrum of options such as verbatim, intelligent verbatim – where stutters, errors, and false starts are corrected – and even summarized notes.
Text to Speech Conversion
Text to speech (TTS) falls within the broad category of assistive technology that outputs text to audio. With the tap of a finger or a mouse click, text to speech programs can take speech and convert it into audio.
Text to speech conversion is useful for people who struggle with reading. It also assists with writing, editing, and improving focus.
Today, just about every digital device has a text to voice converter. All manner of text files can be read aloud, including webpages by activating inbuilt website tools available on-screen, or by using browser plugins and extensions.
The voice is generated by a computer using speech synthesis technology. It can be slowed down or sped up depending on user preferences. The voice quality also varies with each application. Some applications are said to sound more human than others.
There are five main speech to text tools:
- Built-in text-to-speech: Many devices come with built-in TTS tools. Your standard computer, mobile phone, or tablet most likely has one. These can be used without the need for special applications or software.
- Web-based tools: Some websites come with built-in TTS tools. Otherwise, the functionality can be added using a plugin. For example, numerous WordPress plugins let you add a text to voice converter to your website. Website visitors then click on an icon to hear the text read aloud.
- Text-to-speech apps: These are downloadable apps available on The Play Store for Android and App Store for iOS, usually with a rich variety of features.
- Chrome extensions: Chrome comes with several free extensions that read out text aloud. They can be found at the Chrome Web Store.
- Text-to-speech software programs: There are also several stand-alone text-to-speech programs compatible with various operating systems.
Ways to Convert Speech to Text
Let’s examine several ways to convert conversation to text.
Google provides several options to transcribe audio to text free of charge.
The first is through Google Docs Voice to Text, a free audio to text converter. This works with Chrome browsers on Google Docs or Google Slides.
The Google Translate app also converts voice to text. When you open the page, there is a small microphone that allows you to speak into the device. The words are captured, converted to text, and translated to your desired language.
You can also upload an audio file to Google text to speech on Google cloud and create a transcription project. Once the file is transcribed, you can download it or share it online.
Speech to text Android functionality is also a standard feature via Google Assistant.
Windows Dictation
This functionality was built into Windows 10 by Microsoft. You can type a document using your voice by placing your cursor at the location of an MS Word document and speaking into a microphone.
Apple Dictation
Just like in Windows, Apple dictation is a speech to text converter built into a Mac. You simply place your cursor wherever you want the text to appear and speak into the microphone.
Amazon Transcribe
Amazon Transcribe works as an audio file to text converter. You simply upload an audio file to your S3 container and then create a transcription job. Once the file is transcribed you get a notification and can download it or share it.
Other Applications
The top three are the most common due to the sheer number of devices that ship with them as standard features. However, there are hundreds of applications for converting voice to text. They range from simple to advanced tools with a wide range of features.




{kind=link}
{kind=link}